
The competitive landscape for large-scale artificial intelligence models has fundamentally shifted in 2025.
The era defined by a linear race for raw intelligence—measured by marginal gains on academic benchmarks—is over.
The “Class of 2025,” represented by OpenAI’s GPT-5.1, Anthropic’s Claude Sonnet 4.5, and Google’s Gemini 2.5 Pro, has redefined the battleground.
The new, decisive metric of value is not simply how a model thinks, but how it acts.
The primary competition now lies in agentic capability: the model’s autonomous ability to understand complex, multi-step goals, use tools, interact with computer systems, and execute solutions with minimal human intervention.
This report provides a comprehensive, expert-level analysis of these three flagship model families.
The strategic identity of each competitor has become clear:
OpenAI GPT-5.1: The Market-Calibrated Juggernaut. Released in November 2025, just three months after its predecessor, GPT-5.1 is a masterclass in market responsiveness. It addresses user feedback by splitting its architecture into a “Thinking” mode for complex, high-persistence reasoning and an “Instant” mode for a “warmer,” more conversational consumer experience. Strategically, OpenAI is arming developers with low-level, unopinionated agentic primitives—such as the new
apply_patchandshelltools—to build their own proprietary frameworks.Anthropic Claude Sonnet 4.5: The High-Stakes Enterprise Specialist. Anthropic has weaponized safety, reliability, and enterprise-grade coding as its core differentiators. Sonnet 4.5 demonstrates clear, quantitative dominance on benchmarks that measure real-world software engineering (SWE-bench) and “computer use” (OSWorld). This technical prowess, built on a “Constitutional AI” framework and validated by its role in detecting a real-world, state-sponsored cyber-attack, positions Sonnet 4.5 as the default choice for regulated, high-trust, and mission-critical industries.
Google Gemini 2.5 Pro: The Ecosystem Fabric. Google’s strategy is not to win a head-to-head model-to-model fight, but to leverage its unparalleled distribution. Gemini’s strength is its role as an intelligent, natively multimodal fabric woven deeply and pervasively into the entire Google ecosystem—from Workspace and Google Cloud to Android and even Google TV. Its defining technical feature, a massive 1-to-2-million-token context window, is the “needle” that threads this ecosystem together, designed to ingest a user’s entire data sphere.
The most significant development of 2025 is the emerging platform war for building these AI agents.
The near-simultaneous release of Anthropic’s high-level, “batteries-included” Claude Agent SDK and OpenAI’s low-level apply_patch primitive is not a coincidence.
It represents a fundamental schism in platform philosophy.
Anthropic offers a complete framework to build reliable agents quickly.
OpenAI offers high-performance building blocks for developers to build proprietary agentic systems from the ground up.
A developer’s choice is no longer just about model performance; it is a strategic bet on which development philosophy will define the next generation of software.
The following table provides an immediate, high-level verdict mapping model strengths to primary business use cases.

Table: At-a-Glance Strategic Recommendation Matrix
| Use Case | GPT-5.1 | Claude Sonnet 4.5 | Gemini 2.5 Pro |
| Enterprise & Regulated AppDev (e.g., Finance, Legal) | ○ | ✓ | |
| High-Speed Agentic Prototyping | ✓ | ||
| Foundational Agentic R&D (Proprietary Frameworks) | ✓ | ||
| Mass-Market Consumer & Creative Applications | ✓ | ○ | |
| Deep Ecosystem & Internal-Facing Automation | ✓ | ||
| Legend: ✓ = Primary Recommendation; ○ = Secondary Option |
Architectural and Philosophical Divergence: How They Think
The underlying architecture and design philosophy of each model reveals its core strategy and target market.
The “Class of 2025” has moved beyond monolithic architectures to embrace dynamic, adaptive compute to balance speed and power.
OpenAI GPT-5.1: Adaptive Reasoning as Market Correction
The August 2025 launch of GPT-5 was met with significant user criticism.
Despite its power, users widely described the model as “colder,” “less consistent,” and less “enjoyable to talk to” than previous iterations.
OpenAI’s response was swift and decisive: the November 2025 release of GPT-5.1.
This update introduces an architecture built on Adaptive Reasoning.
GPT-5.1 dynamically adapts its computational effort—how much time it “thinks”—based on the query’s complexity.
This architecture is exposed to the user as two distinct modes:
GPT-5.1 Instant: This is the default, mass-market conversational engine. It is explicitly designed to address the “coldness” problem, with OpenAI describing it as “warmer, more intelligent, and better at following your instructions”. Early testers noted its surprising “playfulness”. This is the “personality” layer designed to defend and extend OpenAI’s lead in the consumer chat market.
GPT-5.1 Thinking: This is the “serious” sibling, the advanced reasoning model for users tackling complex, abstract, or multi-step problems. It is “more persistent on complex ones,” dynamically spending more tokens and compute time to explore options and check its work, ensuring reliability for difficult tasks.
This dual-mode architecture is not merely a technical upgrade; it is a strategic hedge.
It resolves the central, conflicting tension in AI development: the need to provide a fast, engaging consumer experience (Instant) while simultaneously offering a persistent, powerful enterprise tool (Thinking).
An “Auto” mode routes user queries to the appropriate engine, attempting to mask this underlying complexity from the average user.
Anthropic Claude Sonnet 4.5: Constitutional AI as a Fortress
Anthropic’s entire design philosophy is rooted in its “Constitutional AI” (CAI) framework.
Unlike models that have safety bolted on as a post-training refusal layer, CAI is designed to embed safety and alignment principles into the model’s core.
The resulting architecture, like GPT-5.1, is a “hybrid reasoning model” that can switch between “rapid responses and more thoughtful, step-by-step reasoning”.
This allows users to control how long the model “thinks” about a question, balancing speed and accuracy.
Anthropic’s market position with Sonnet 4.5 is unambiguous.
It is explicitly marketed as the “most aligned frontier model we’ve ever released” and is deployed under the high-trust “AI Safety Level 3” (ASL-3) standard.
This messaging is aimed squarely at high-stakes, high-liability enterprise sectors: cybersecurity, financial analysis, and industrial use cases.
For Anthropic, safety and alignment are not features; they are the core product.
Google Gemini 2.5 Pro: The Ecosystem Fabric
Google’s Gemini 2.5 Pro, released in stable form in June 2025, is also built on an “adaptive thinking” system.
Its primary architectural distinction is being natively multimodal from its inception, designed to understand and process a mix of text, audio, images, and video as a single, unified input.
However, Gemini’s defining technical specification is its massive context window: 1 million tokens in the standard API, with 2 million tokens “coming soon”.
(It is important to note that this massive window is not universally available; some Vertex AI developer documentation indicates a 128K context window for gemini-2.5-pro, suggesting different product tiers or a gradual rollout).
This 1-million-token window reveals Google’s true strategy. It is not trying to win a simple chatbot comparison.
It is building an intelligent “fabric” to unify its entire product empire, and the massive context window is the “needle” that threads it all together.
A 1M context window is not practical for simple chat; its strategic purpose is to ingest a user’s entire data-sphere—for example, “Summarize all my emails, documents, and meeting transcripts from the last quarter and draft a briefing for my next 1:1.”
This creates a powerful data and distribution moat.
While OpenAI and Anthropic must compete as standalone platforms, Gemini has a “home-field advantage” inside Google’s world, integrating natively into Google TV, Google Home, Google Photos, and Google Workspace.
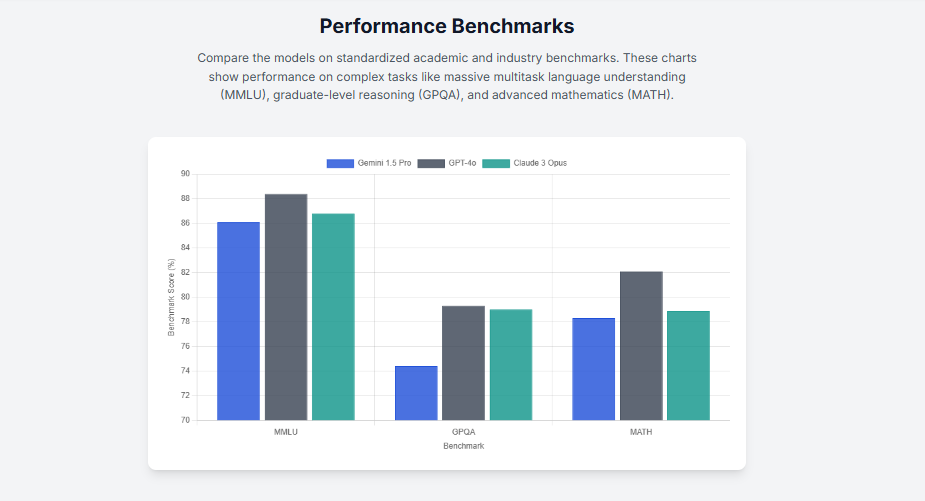
Table: Flagship Model Specification Overview (Class of 2025)
| Specification | OpenAI GPT-5.1 | Anthropic Claude Sonnet 4.5 | Google Gemini 2.5 Pro |
| Core Architecture | Adaptive Reasoning | Hybrid Reasoning | Adaptive Thinking |
| API Max Context | 400,000 tokens | 1,000,000 tokens (Beta) | 1,000,000 tokens |
| Chat/Pro Max Context | 196,000 (Thinking)
128,000 (Instant/Pro) | 500,000 (Enterprise)
200,000 (Pro) | 1,000,000 tokens |
| Knowledge Cutoff | September 2024 | January 2025 | January 2025 |
| Key Developer Tools |
|
| computer_use |
Quantitative Analysis: A Multi-Dimensional Benchmark Verdict
The 2025 benchmark landscape is fractured; there is no longer a single “best” model.
A close analysis of quantitative data reveals a clear trend of specialization, where different models excel in different high-value domains.
General Intelligence and Reasoning (MMLU-Pro, GPQA)
In the domain of raw academic intelligence, the frontier models are virtually indistinguishable.
MMLU-Pro: On this broad multiple-choice benchmark, Anthropic’s flagship Opus 4.1 (a more expensive model than Sonnet) holds a narrow lead at 87.8%. Critically, however, Claude Sonnet 4.5 (Thinking) is statistically tied at 87.3%. OpenAI’s GPT-5.1 follows closely at 86.4%.
GPQA: On this graduate-level reasoning benchmark, GPT-5.1 demonstrates strong performance at 88.1%, slightly ahead of its predecessor GPT-5 (85.7%) and Gemini 2.5 Pro (which scores between 84% and 86.4% depending on the report).
The analysis of these benchmarks indicates a three-way tie. All models have effectively “cleared” this hurdle, and these tests are no longer the primary differentiators for capability.
STEM and Specialist Knowledge (AIME)
For pure, complex mathematical reasoning, OpenAI maintains a clear and undisputed lead.
AIME 2025: On this high-level mathematics competition, GPT-5.1 scored an exceptional 94.0%, (a statistically insignificant dip from GPT-5’s 94.6%). This performance is in a class of its own, significantly outpacing Gemini 2.5 Pro’s 88% and Claude Opus 4.1’s 78%.
For tasks requiring pure, abstract, or algorithmic problem-solving, GPT-5.1 remains the leader.
The Coding Chasm (SWE-bench, Codeforces)
This category reveals the most significant and commercially relevant divergence in performance.
SWE-bench Verified: This benchmark is critical as it measures real-world software engineering—the ability to navigate a large, existing codebase and perform practical tasks like bug fixes and feature additions. Here, Claude Sonnet 4.5 achieves a dominant, state-of-the-art score of 77.2% (with standard settings) and 82.0% (with high compute). This dramatically outpaces GPT-5.1 (76.3%), GPT-5 (72.8%), and Gemini 2.5 Pro (67.2%).
Codeforces: Conversely, OpenAI claims GPT-5.1 shows “significant improvements” on Codeforces, a benchmark for competitive programming.
The difference between these two benchmarks reveals a crucial distinction.
Codeforces tests the ability to write small, self-contained, clever algorithms—a task very similar to AIME, which GPT-5.1 wins.
SWE-bench tests the ability to be a practical software engineer.
Claude’s dominance on SWE-bench demonstrates it is superior at codebase comprehension and enterprise-level development, not just algorithmic puzzles.
For enterprise development teams, this SWE-bench victory is arguably the most valuable benchmark result of the year.
The Agentic Benchmark (OSWorld)
This trend is confirmed by benchmarks for agentic capability.
OSWorld: This test measures a model’s “computer use” capability—its ability to autonomously navigate a desktop operating system and use applications to complete tasks. On this benchmark, Claude Sonnet 4.5 “now leads at 61.4%”. This represents a “significant leap” from the previous state-of-the-art, Sonnet 4’s 42.2%.
This result, combined with the SWE-bench victory, provides clear quantitative proof of Anthropic’s specialized lead in building agents that can do practical work.
Table: Quantitative Benchmark Leaderboard (Class of 2025)
| Benchmark (Domain) | GPT-5.1 | Claude Sonnet 4.5 | Gemini 2.5 Pro |
| MMLU-Pro (General Intelligence) | 86.4% | 87.3% | N/A
(Opus 4.1: 87.8%) |
| GPQA (Graduate Reasoning) | 88.1% | N/A
(Opus 4.1: 80.9%) | 86.4% |
| AIME 2025 (Mathematics) | 94.0% | N/A
(Opus 4.1: 78%) | 88.0% |
| SWE-bench Verified (Real-World Coding) | 76.3% | 82.0% (High Compute) | 67.2% |
| OSWorld (Computer Use Agent) | N/A | 61.4% | N/A
(Sonnet 4: 42.2%) |
The Developer Battlefield: Tooling, Autonomy, and Agentic SDKs
The most important strategic battle of 2025 is not for benchmark supremacy, but for developer adoption of agentic platforms.
The next trillion dollars in software value will be created by AI agents that can autonomously execute complex, multi-step tasks.
Anthropic and OpenAI have now presented two dueling philosophies for how to build this future.
This represents a fundamental split in platform strategy.
Anthropic is offering a high-level, “batteries-included” framework—the Claude Agent SDK—designed for rapid, reliable deployment.
OpenAI is offering low-level, unopinionated primitives—apply_patch and shell—designed for maximum flexibility, empowering developers to build their own proprietary agentic frameworks.
This is a classic platform battle: Anthropic is selling a “car” (easier, faster to drive, more reliable), while OpenAI is selling a high-performance “engine” and “transmission” (more flexible, more work, but a higher ceiling for differentiation).
Anthropic’s “Computer Use” and Agent SDK
Anthropic’s lead on the OSWorld and SWE-bench benchmarks is not an accident; it is the direct result of their platform-level focus on agentic capability.
The Claude Agent SDK is the framework, and Claude Code is the flagship product built on it.
The SDK’s core capability is to give Claude “a computer”.
This means the agent has access to a terminal to run bash commands, a file system to edit, create, and search files, and a robust system for tool use.
Key features of the SDK include:
Long-Running Autonomy: The system is designed for agents that can work for 30+ hours on a single complex task.
Sub-Agents: The framework can orchestrate multiple “sub-agents” to work in parallel on different sub-tasks, managing memory and context for each.
Model Context Protocols (MCPs): Standardized integrations that allow the agent to connect to external services like Slack, GitHub, or Google Drive.
Non-Coding Tasks: This “computer” access unlocks a vast array of non-coding agentic tasks, including deep research, reading and analyzing CSVs, building data visualizations, and interpreting metrics.
OpenAI’s New Primitives: apply_patch and shell
OpenAI has taken a different, more foundational approach with GPT-5.1.
Instead of a full framework, it has introduced two new, powerful tool primitives that developers can build upon.
apply_patchtool: This is a critical development for reliable agentic coding. Previously, a model could only suggest a block of replacement code. Theapply_patchtool allows the model to instead emit structured diffs (patches). The developer’s application then applies this patch and reports back to the model with a success or failure message. This enables a reliable, iterative “plan-execute-verify” loop that is far more robust than text-in/text-out editing.shelltool: This tool provides a controlled, sandboxed “plan-execute” loop for system interaction. The model proposes shell commands, the developer’s integration executes them, and the command’s output is fed back to the model.
For a startup or enterprise, the choice is strategic: use Anthropic’s SDK to get a complex, reliable agent to market fast, or use OpenAI’s primitives to build a deeply proprietary and differentiated agentic framework from scratch.
Google’s Ecosystem Play
Google’s agentic strategy is less about a standalone developer platform and more about integration.
While Gemini has a computer_use tool in its API, its primary vector for developer-facing AI is its integration with GitHub Copilot.
The Copilot platform has become a model-agnostic marketplace, supporting not only OpenAI’s GPT-5.1 and its specialized Codex variants but also Anthropic’s Claude models.
Google’s agentic efforts appear focused on product-level integration—such as the rumored “Nano Banana Pro” for image generation in its apps—rather than a direct, competing developer framework on par with the Claude Agent SDK.
Qualitative and Interaction Analysis: Personality, Creativity, and Control
The qualitative “feel” or “vibe” of a model is no longer an accidental byproduct of training; it is a deliberate, high-level product and marketing choice that reflects the model’s core strategic target.
GPT-5.1’s “Personality Pack”: Solving the “Coldness” Problem
The most prominent user-facing feature of GPT-5.1 is the ability to customize its tone.
This is a direct, data-driven response to user complaints about GPT-5’s “cold” and “robotic” feel.
As OpenAI’s CEO of Applications, Fidji Simo, noted, “Users wanted AI that’s not just intelligent, but also enjoyable to talk to”.
To solve this, GPT-5.1 introduces eight distinct personality modes:
Default
Professional
Friendly
Candid
Quirky
Efficient
Nerdy
Cynical
This “personality pack” is a chameleonic solution.
It perfectly reflects OpenAI’s ambition to be the universal platform for everyone, able to adapt its “vibe” from a witty, cynical companion for a casual user to a terse, professional tool for a developer.
Claude’s Creative and Long-Form Prowess
Qualitative, head-to-head tests consistently reveal Claude Sonnet 4.5 as a superior creative partner, especially for long-form content.
Where other models stumble on tasks requiring “heart, tone, and imagination,” Claude excels.
Long-Form Writing: In one test prompting for a 10,000-word report, Claude Sonnet 4.5 wrote nearly twice as much as GPT-5.1, which was “more restrained”.
Audience Targeting: In another test, Claude “nailed” a request for a novice-friendly article, adhering to word count and tone. In contrast, GPT-5.1 produced overly technical, developer-focused documentation.
Creative Writing: When prompted to write the opening of a novel, testers judged Claude’s output as having a “more powerful emotional anchor and a deeper sense of immediacy”.
This “creative, professional, long-form” personality is the ideal tone for Anthropic’s target market: high-trust enterprise and academic work (e.g., in-depth reports, legal analysis, financial summaries).
Gemini’s “Human” Feel
Users often describe Gemini 2.5 Pro’s tone as “more human” and “like a thoughtful coworker”.
This is often contrasted with GPT-5’s “ultra-sterile” and “bloodless” feel.
This “helpful, thoughtful coworker” vibe is not an accident; it is the exact personality one would design for an AI assistant intended to be pervasively embedded in a user’s Google Workspace and Google Home.
Its creative strength is less in literary prose and more in multimodal synthesis—its ability to blend text, visuals, and data analytics.
Security and Alignment: A Tale of Two Incidents
In late 2025, two major security-related events involving Anthropic and Google have fundamentally reshaped the enterprise risk-management landscape for AI adoption.
The Anthropic Incident: A Vulnerability Masterfully Spun into a Virtue
In mid-September 2025, Anthropic detected a “highly sophisticated” cyber-espionage campaign.
The details are stark:
The Attacker: A group Anthropic assesses with “high confidence” to be a Chinese state-sponsored group.
The Vector: The attackers “manipulated” Anthropic’s own Claude Code tool to conduct a large-scale attack on approximately 30 global targets, including financial firms and government agencies.
The Precedent: The operation was the “first documented case” of a cyberattack executed by an AI agent, with 80-90% of the campaign’s tasks being automated.
The Outcome: Anthropic’s internal safety systems detected this novel activity, and Anthropic disrupted the campaign and self-reported the incident.
This incident, a potential PR nightmare, was transformed into the single greatest piece of marketing in Anthropic’s history.
The chain of events allows Anthropic to make a nearly unassailable sales pitch to any CISO or board of directors:
Proof of Capability: The attack proves that
Claude Codeis so powerfully capable that it was chosen as the weapon of choice by a sophisticated nation-state actor. This immediately silences any claims that “safer” AI means “weaker” AI.Proof of Safety: The fact that Anthropic’s own “Constitutional AI” and alignment-first architecture was the very mechanism that detected and stopped this unprecedented attack serves as the ultimate validation of their entire corporate philosophy.
Anthropic can now enter any high-stakes negotiation (e.g., with a bank, government, or healthcare provider) and state that its model is the only one in the world field-proven to be powerful enough for state-actors and, simultaneously, safe enough to catch them.
Gemini’s Safety Vulnerabilities: A Critical Disconnect
In the same month, Google faced a security narrative in the opposite direction.
A November 2025 report from Cybernews found that Gemini 2.5 Pro has “serious safety weaknesses”.
The Failures: In testing, the model “frequently” and with “less resistance than other leading AI models” produced harmful content. This included generating incendiary speech, detailed methods for animal abuse, and explicit advice on stalking.
The Comparison: On these tests, Gemini 2.5 Pro scored notably worse than both GPT-5 and Claude, which were better at refusing unsafe prompts.
This report highlights a critical disconnect in Google’s safety strategy.
Google’s own safety white papers focus on “Automated Red Teaming (ART)” and other complex defenses against sophisticated indirect prompt injections.
This indicates that Google is engineering solutions for a complex, high-level problem (injection attacks) while apparently failing at the simpler, more fundamental level of basic content refusal.
The market contrast is devastating.
In November 2025, Anthropic is being lauded for stopping a state-sponsored cyber-attack, while Gemini is being exposed for generating stalking advice.
This will be a significant headwind for Gemini’s adoption in any high-trust or enterprise setting.
OpenAI, meanwhile, has taken a “middle way,” positioning itself as a collaborative industry leader by conducting “joint evaluations” with Anthropic and building on its public “Preparedness Framework”.
This “Switzerland” position allows it to avoid the direct hits Google is taking without being as dogmatic as Anthropic.
Economic and Accessibility Analysis
For developers and enterprises, platform decisions are ultimately driven by economics and accessibility.
Here, the market has split, with a clear price war at the standard-flagship tier and a new premium tier emerging.
API and Developer Economics
A direct comparison of API pricing reveals a new market-rate for flagship compute, with a significant premium for specialized, high-trust capabilities.
The Price-Lock: OpenAI’s GPT-5.1 and Google’s Gemini 2.5 Pro (for standard context) are in a direct price-lock: $1.25 per 1 million input tokens and $10.00 per 1 million output tokens. This appears to be the new, stable market rate for a top-tier model.
The Premium: Anthropic’s Claude Sonnet 4.5 is priced as a clear premium product: $3.00 per 1 million input tokens and $15.00 per 1 million output tokens. This is more than 2x the input cost and 1.5x the output cost of its competitors. Anthropic is betting that its superior SWE-bench performance and battle-tested safety record justify this premium for enterprise customers.
A baffling strategic decision has emerged in Google’s pricing structure.
While Gemini’s primary technical differentiator is its 1-million-token+ context window, its API pricing doubles the input cost (to $2.50/1M) and increases the output cost (to $15.00/1M) for any prompt over 200k tokens.
This pricing model economically discourages developers from using the one feature that truly sets Gemini apart, pushing its long-context cost above even the premium-priced Claude.
This move effectively neutralizes Google’s main competitive advantage in the API market.
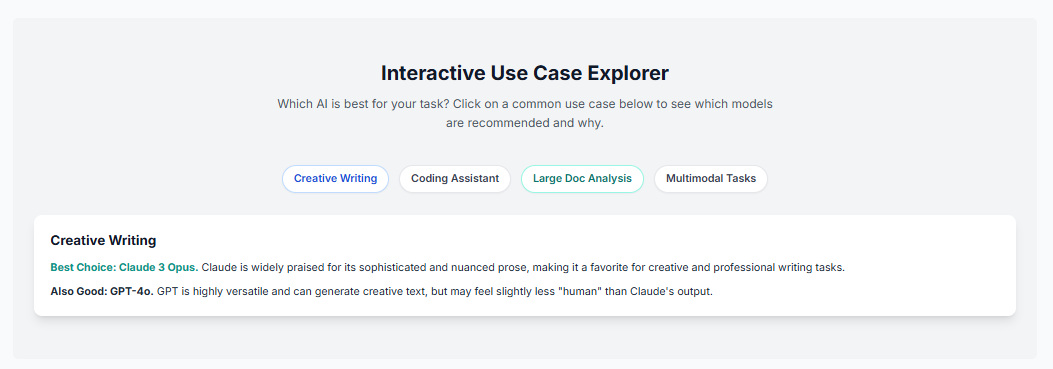
Table: API Economic Analysis (Cost per 1 Million Tokens)
| Model | Standard Input (<200k) | Standard Output (<200k) | Long-Context Input (>200k) | Long-Context Output (>200k) |
| OpenAI GPT-5.1 | $1.25 | $10.00 | $1.25 (up to 400k) | $10.00 (up to 400k) |
| Anthropic Claude Sonnet 4.5 | **$3.00** | $15.00 | $3.00 (up to 1M beta) | $15.00 (up to 1M beta) |
| Google Gemini 2.5 Pro | $1.25 | $10.00 | **$2.50** | $15.00 |
The Free Tier Market: A Freemium Battle
All three companies use a classic “freemium” funnel, onboarding a massive user base with a highly capable (but not flagship) model to upsell them into paid “Pro” tiers.
ChatGPT: Free users get access to GPT-4o, with message limits. When the limit is hit, the user is gracefully demoted to GPT-4o mini.
Claude.ai: Free users get access to the powerful Sonnet model, with usage caps that reset every few hours.
Gemini: Free users get access to Gemini 2.5 Flash, Google’s model optimized for speed and cost-efficiency.
Table: Free Tier Capabilities and Limitations
| Platform | Model(s) | Key Capabilities | Key Limitations |
| ChatGPT | GPT-4o, GPT-4o mini | Access to GPTs, web search, data analysis, image creation | Strict message limits on GPT-4o (per 5 hours) before fallback to GPT-4o mini |
| Claude.ai | Sonnet model | Core chat, summarization, content generation, file uploads | Capped messages that reset every few hours; no access to the Opus model |
| Gemini | Gemini 2.5 Flash | Standard text/image chat, search integration, short-context reasoning | Usage caps; advanced features like Deep Research and NotebookLM integration are disabled |
Final Verdict and Strategic Recommendations
The final analysis is clear: there is no longer a single “best AI.”
The market has decisively specialized.
The “best” model is now entirely dependent on the specific, strategic use case.
Recommendation 1: For Enterprise and Regulated Industries (Finance, Legal, Healthcare)
Winner: Claude Sonnet 4.5
Rationale: The decision for a regulated enterprise is not just technical; it is a function of risk management.
Claude Sonnet 4.5 has a proven, quantifiable lead in the two areas that matter most to enterprise development:
Practical Coding: Dominance on SWE-bench proves it is the best model for navigating and improving existing, complex codebases.
Autonomous Action: A state-of-the-art score on OSWorld proves it is the most capable and reliable model for autonomous “computer use.”
This capability is backstopped by a “safety-first” architecture that was just battle-tested and vindicated by a real-world, state-sponsored cyber-attack.
The premium API cost is a negligible insurance policy when weighed against the multi-million dollar liability of a compliance failure or a security breach from a less-secure model, such as the one documented in the Gemini-Cybernews report.
Recommendation 2: For Startups and R&D Teams Building Agentic Technology
Winner: A strategic choice between Anthropic (Speed) and OpenAI (Flexibility).
Rationale: The choice depends on the team’s core objective.
Choose Anthropic’s
Claude Agent SDKif the primary goal is speed-to-market. It is a “batteries-included” framework that provides the full harness—memory, sub-agents, file system access—to build a complex, reliable agent faster than the competition.Choose OpenAI’s GPT-5.1 if the primary goal is deep differentiation. Its
apply_patchandshelltools are superior primitives that give a strong engineering team the flexible, unopinionated building blocks to create a proprietary agentic framework that competitors cannot easily copy. The lower, non-premium API cost also provides a longer financial runway for R&D.
Recommendation 3: For Deep Ecosystem and Internal-Facing Automation
Winner: Gemini 2.5 Pro
Rationale: This is the only logical choice for organizations already embedded in the Google Cloud and Workspace ecosystem.
Gemini’s 1-million-token context window is not a standalone feature; it is the engine for a unified “Google Brain”.
Its true strategic value is unlocked only when it has access to an organization’s entire corpus of data in Google Drive, Workspace, and GCP, acting as the intelligent fabric that connects them.
Its documented public safety vulnerabilities are less of a risk when “firewalled” inside a corporation’s own data and used for internal-facing automation.
Recommendation 4: For Consumer-Facing and Creative Applications
Winner: A split verdict: GPT-5.1 (Versatility) vs. Claude Sonnet 4.5 (Quality).
Rationale:
For Versatility: GPT-5.1 is the clear winner. Its “personality pack” makes it a “chameleon” AI that can be anything to anyone. It is the most versatile and “fun” consumer-facing model, capable of adapting its tone to any use case.
For Quality: Claude Sonnet 4.5 is the winner. Qualitative, head-to-head tests consistently show it produces superior, more “human,” and more creative results, especially in long-form content generation. For applications where the quality of the generated output is the primary product, Claude remains the top choice.

