

Part 1: The Core Components of Conversational AI
1.1 Deconstructing “Intelligent” Conversation in 2025
The definition of an “intelligent” chatbot has undergone a profound transformation.
In 2025, conversational AI is no longer judged by its ability to answer simple, predefined questions.
Instead, it is evaluated on a complex matrix of human-centric capabilities that mimic true understanding and adaptability.
This new standard of intelligence is defined by several key attributes:
Linguistic Diversity and Nuance: Modern systems are expected to handle the full spectrum of human language, moving far beyond formal grammar. This includes the ability to parse and understand complex linguistic patterns, such as colloquial expressions, regional dialects, and professional jargon. An intelligent agent in 2025 must comprehend both Australian slang and Appalachian vernacular without failing.
Persistent Contextual Awareness: The era of amnesiac, session-based interactions is over. True intelligence is now demonstrated through the ability to maintain conversation context over multiple interactions. This means the AI must remember user preferences, recent queries, and even shared “inside jokes,” eliminating the user frustration of “starting over” with every new conversation.
Emotional Nuance and Empathy: Advancements in Natural Language Understanding (NLU) are enabling systems to become “emotionally intelligent”. This capability transcends simple positive/negative sentiment analysis. A 2025-era bot can detect subtle feelings like frustration in a user’s voice or text and adapt its own response accordingly, perhaps by adopting a more soothing or patient tone. This ability to escalate the customer experience based on mood is a critical differentiator.
For a developer, building for this new standard requires more than just technical skill; it requires a new form of “AI Literacy”.
This framework, as outlined by researchers at Stanford, identifies intersecting domains of understanding essential for development:
-
Functional Literacy: How does the AI actually work?
-
Ethical Literacy: How do we navigate the complex ethical issues of AI?
-
Rhetorical Literacy: How do we use both human and AI-generated language to achieve specific goals?
-
Pedagogical Literacy: How do we use AI to enhance learning and teaching?
This report is designed to provide comprehensive training across all these domains, beginning with the functional components that power every conversation.
Supercharge your business growth with Peno AI, the all-in-one platform for intelligent sales and marketing automation.
We deliver transformative AI solutions designed to redefine how you operate, from precisely identifying and qualifying high-potential leads to generating high-quality, on-brand content at scale.
Our services seamlessly integrate across all your key platforms, including WhatsApp, LinkedIn, and YouTube, providing custom-tailored automations that free your team to focus on strategy and building customer relationships. Stop chasing leads and start closing more deals with Peno AI’s powerful, data-driven solutions.
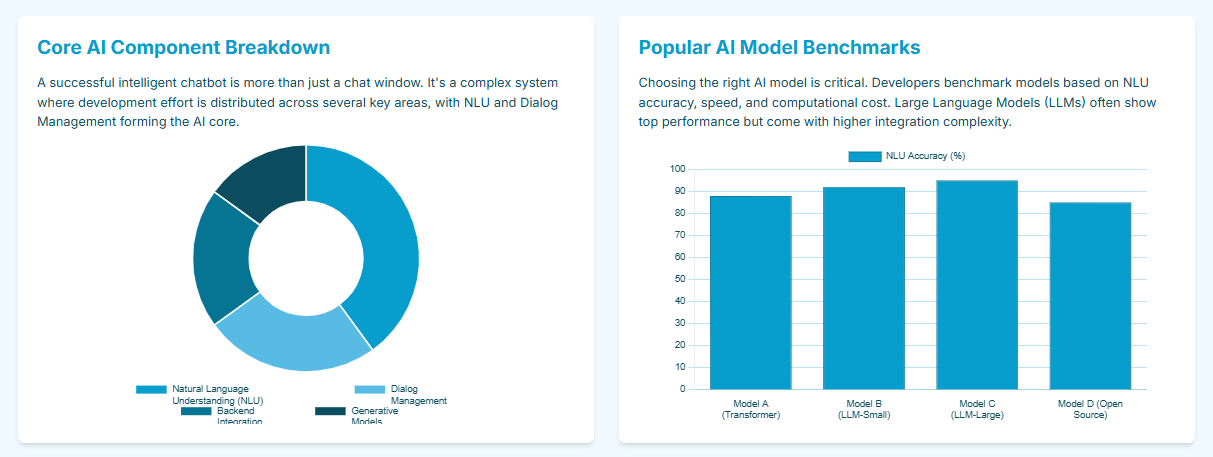
1.2 The Communication Loop: NLP, NLU, and NLG
To build an intelligent chatbot, one must first understand the three distinct yet synergistic technologies that form the complete AI communication loop: Natural Language Processing (NLP), Natural Language Understanding (NLU), and Natural Language Generation (NLG).
These terms are often confused, but they have a clear and critical hierarchy.
NLP is the broad, overarching field, while NLU and NLG are specific components within that field.
Natural Language Processing (NLP): This is the macro-discipline, a branch of Artificial Intelligence (AI) that helps machines understand and process human language in both text and audio forms. NLP acts as the “backbone” for all chatbot communication, encompassing the entire process from input to output. This includes foundational tasks like text preprocessing (e.g., tokenization, stemming), speech recognition, translation, and text summarization.
Natural Language Understanding (NLU): This is the input and comprehension component of the loop, and a subset of NLP. Its specific function is to parse the user’s raw query and convert unstructured text into structured, machine-readable data. NLU “zeroes in on interpreting context, sentiment, and intent”. This is where the core tasks of intent classification (identifying what the user wants to do, e.g., ‘book a flight’) and entity extraction (pulling out specific details, e.g., ‘New York’, ‘tomorrow’) occur.
Natural Language Generation (NLG): This is the output and response component, also a subset of NLP. After the bot decides what to say, NLG’s role is to take that structured decision and “convert structured data… into coherent, contextually appropriate human language”. This technology is responsible for the increasingly “natural voice synthesis” that is replacing robotic tones in 2025.
This analysis reveals that the 2025-era trends defined in the previous section—understanding slang, detecting emotional nuance, and maintaining context—are all fundamentally NLU challenges.
The perceived “intelligence” of a modern chatbot is therefore less about its generative fluency (NLG), which has been largely commoditized by large models, and more about its deep, precise, and emotionally-aware interpretive ability (NLU).
A bot that fails to understand a user’s frustration has failed at NLU, regardless of how beautifully its NLG component generates the “I’m sorry, I don’t understand” response.

1.3 The “Brain”: Dialogue Management
Sitting between the NLU’s input and the NLG’s output is the component that acts as the chatbot’s “brain”: Dialogue Management.
After NLU has successfully identified the user’s intent and entities, the Dialogue Management system takes over.
Its job is to decide how to respond based on the user’s query, the current context, and the bot’s predefined logic or goals.
This component is what enables a stateful, multi-turn conversation, differentiating a true AI assistant from a simple, stateless Q&A bot.
It tracks the conversation’s state, remembers previous user inputs, and determines the “next best action,” which it then passes to the NLG component to be articulated.
Table 1: NLP vs. NLU vs. NLG: A Comparative Analysis
| Feature | Natural Language Processing (NLP) | Natural Language Understanding (NLU) | Natural Language Generation (NLG) |
| Primary Function | The broad, end-to-end field of processing and generating human language. | Comprehension & Interpretation: Understands the meaning and intent of user input. | Creation & Response: Generates human-like, coherent text or speech as output. |
| Scope | Broad Field. Encompasses NLU, NLG, speech-to-text, translation, and more. | Subset of NLP. Focused on the input side of the communication loop. | Subset of NLP. Focused on the output side of the communication loop. |
| Key Techniques | Tokenization, syntax parsing, named entity recognition (NER), machine translation. | Intent Classification, Entity Extraction, Sentiment Analysis, Context Handling. | Text Structuring, Sentence Planning, Converting structured data to natural language. |
| Example in Chatbots | The entire system that allows a user to speak in Hindi and the bot to reply in Spanish. | User types: “I need a flight to Boston for $300.” NLU extracts: Intent: ‘book_flight’, Entity_Destination: ‘Boston’, Entity_Price: ‘$300’. | Bot’s internal decision: {Status: ‘Success’, Flight: ‘AA123’, Price: ‘$295’}. NLG generates: “I found a flight for you to Boston on AA123 for $295.”. |
Part 2: The Foundational Shift: LLMs and Modern AI Architecture
The most significant change in AI development over the last few years has been a complete paradigm shift in how models are built.
This shift is the engine behind the 2025 “intelligent chatbot” and moves development away from training small, specialized models and toward adapting massive, general-purpose ones.
2.1 The Paradigm Shift: From Task-Specific to Foundation Models
The traditional approach to machine learning involved training models on relatively smaller, labeled datasets to accomplish specific, narrow tasks.
A team would build one model for sentiment analysis, a separate model for translation, and a third model for topic classification.
The new paradigm is that of Foundation Models. This term describes a class of massive AI models that are:
-
Trained on vast, immense datasets of unlabeled data (e.g., the entire internet).
-
Trained using self-supervised learning, where the model learns patterns from the data itself without human-provided labels.
-
General-purpose, meaning they are not pre-trained for any single, narrow task.
The key benefit of this approach is adaptability.
Because these models are pre-trained on general-purpose data, they acquire a broad “knowledge” of language, facts, and reasoning.
They can then be easily adapted (or “fine-tuned”) to a wide range of specialized tasks.
This model of development shifts the AI workflow from “building from scratch” to “adapting a powerful, pre-existing base,” dramatically increasing efficiency and capability.
2.2 The Engine of Modern AI: The Transformer Architecture
The core technical innovation that enabled the creation of foundation models is the Transformer Architecture.
This neural network design was introduced in the seminal 2017 Google paper, “Attention is All You Need”.
Prior to the Transformer, the dominant architectures were Recurrent Neural Networks (RNNs) and their variants (like LSTMs).
RNNs processed text word-by-word, in sequence. This sequential nature made them difficult to parallelize and created a “bottleneck” that made it difficult to remember context over long sentences.
The Transformer architecture’s core innovation was replacing this recurrence with a mechanism called self-attention.
Self-attention allows the model to look at the entire input sequence at once, weighing the “importance of different words in relation to each other”.
It learns complex grammatical, syntactic, and semantic relationships between all tokens in a sequence, effectively capturing long-range dependencies.
This design breakthrough was the lynchpin for the modern AI revolution.
The self-attention mechanism “allowed efficient parallelization, longer context handling, and scalable training on unprecedented data volumes”.
This scalability is the direct cause of the LLM revolution.
Without the Transformer’s ability to be parallelized, it would be computationally infeasible to train models with the billions or trillions of parameters that define a “Large Language Model.”
Architecturally, a full Transformer consists of two parts:
-
The Encoder: Processes the input text and converts it into a rich numerical representation (an “embedding”) that captures deep context.
-
The Decoder: Takes that representation and generates the output text, token by token.
2.3 The Rise of Large Language Models (LLMs)
A Large Language Model (LLM)—such as those in the GPT, Llama, Gemini, and Claude families—is a type of foundation model, almost always built using the Transformer architecture.
LLMs are typically “Generative Pre-trained Transformers” (GPTs).
They are pre-trained on a simple, self-supervised principle: next-token prediction.
The model is fed trillions of words from books, articles, and websites, and its only job is to predict the most probable next word (or “token”) in a sequence.
When this simple objective is scaled to models with billions or trillions of parameters (the internal coefficients learned from data), an incredible phenomenon occurs: emergent behavior.
The model isn’t just “predicting text”; it demonstrates surprising capabilities in summarization, translation, question-answering, code generation, and even compositional reasoning.
These capabilities were not explicitly programmed; they emerged from the model learning the deep statistical patterns of language and knowledge.
This shift to LLMs fundamentally changes the developer’s role.
In the pre-LLM era (e.g., traditional chatbot frameworks), a developer’s primary task was the painstaking creation of labeled data to train the NLU for intent classification and entity extraction.
This was a training-heavy process.
With modern “pre-trained” foundation models, the model already understands language.
The developer’s job shifts from NLU training to knowledge adaptation. As will be explored, this adaptation is now achieved through three main techniques:
-
Prompt Engineering: Guiding the model’s output through carefully crafted instructions.
-
Retrieval-Augmented Generation (RAG): Providing the model with external, real-time knowledge.
-
Fine-Tuning: Adjusting the model’s parameters for a specific style or task.
Part 3: Customizing the Knowledge Core: RAG vs. Fine-Tuning
The primary challenge of using pre-trained LLMs is that their knowledge is general, static, and disconnected from proprietary business context. This leads to the “grounding problem.”
3.1 The Grounding Problem: Why LLMs Need Help
Despite their impressive capabilities, “off-the-shelf” LLMs have critical flaws that make them unsuitable for enterprise use without customization:
-
Hallucinations: LLMs are trained to be “plausible,” not “truthful.” They can “hallucinate”—generating incorrect, misleading, or nonsensical information with absolute confidence.
-
Stale Knowledge: An LLM’s knowledge is static, limited to the date its pre-training data was collected. It has no access to real-time events, “fresh information,” or data created after its training run.
-
No Access to Proprietary Data: A public LLM does not know your company’s internal product manuals, HR policies, or customer support knowledge bases.
The solution to this “grounding problem” is to connect the LLM to a reliable source of factual, up-to-date, and proprietary information.
The two primary architectures for achieving this are Retrieval-Augmented Generation (RAG) and Fine-Tuning.
3.2 In-Depth Analysis: Retrieval-Augmented Generation (RAG)
RAG is an AI framework that augments the LLM’s generative process with an external retrieval step.
Instead of relying on its (stale) internal memory, RAG redirects the LLM to retrieve relevant information from authoritative, pre-determined knowledge sources before generating an answer.
The RAG architecture can be broken down into a four-stage process:
-
Ingestion & Embedding (Indexing): First, the proprietary knowledge base (e.g., product manuals, FAQs, support tickets, PDFs) is loaded and segmented into smaller “chunks”. Each chunk is then fed into an embedding model, which converts the text into a high-dimensional numerical representation (an embedding vector) that captures its semantic meaning.
-
Storage: These embedding vectors are loaded and indexed into a specialized Vector Database (e.g., Pinecone, FAISS, Chroma). This database is optimized for extremely fast similarity search.
-
Retrieval: When a user submits a query, the query itself is first converted into an embedding vector using the same model. The vector database is then searched to find the document chunks whose vectors are most semantically similar to the query vector.
-
Augmentation & Generation: These “relevant retrieved data” chunks are then augmented into the LLM’s prompt, along with the original user query. The LLM is given a final instruction, such as: “You are a helpful assistant. Answer the user’s question based only on the following context,” followed by the retrieved chunks.
This RAG approach is the single most effective method for solving the grounding problem, as it:
-
Reduces Hallucinations: It “grounds” the LLM in “facts,” forcing it to base its answers on the retrieved text rather than its internal, and potentially incorrect, knowledge.
-
Ensures Data Freshness: It provides access to dynamic, up-to-the-minute information. To update the bot’s knowledge, one simply updates the documents in the vector database—no costly retraining is required.
-
Provides Verifiability: The bot can cite its sources, pointing the user to the exact document chunk it used to formulate the answer. This builds user trust and allows for cross-checking.
-
Enhances Security & Privacy: Proprietary data remains in a secure, private database. It is not “baked into” the model’s parameters, which is a critical consideration for data governance.
3.3 In-Depth Analysis: Fine-Tuning
Fine-tuning is a completely different approach.
It is the process of retraining a pre-trained foundation model on a smaller, domain-specific, labeled dataset.
This process adjusts the model’s internal weights (or parameters) to optimize it for a new, specialized task or domain.
Given that foundation models have billions of parameters, “full fine-tuning” (retraining all weights) is extremely compute-intensive and costly.
For this reason, the 2025 standard is PEFT (Parameter-Efficient Fine-Tuning).
PEFT techniques adjust only a small fraction of the model’s total parameters, dramatically reducing compute and memory requirements.
The most popular PEFT method is LoRA (Low-Rank Adaptation), which freezes the pre-trained model’s weights and injects small, trainable “adapter” matrices. This makes fine-tuning accessible without requiring a supercomputer.
3.4 The Core Dichotomy: RAG is for Knowledge, Fine-Tuning is for Behavior
A common question from developers is, “I have 200 pages of documentation. Should I use RAG or fine-tune the model on it?”.
The expert-level answer, and the most critical architectural insight of this section, is that this question presents a false choice.
RAG and fine-tuning are not interchangeable; they solve different problems.
RAG is for KNOWLEDGE. As one developer community expert notes, “RAG for knowledge. A fine-tune won’t be able to accurately represent the knowledge you train it on”. RAG is superior for “dynamic, up-to-date knowledge” and “trustworthy… factual questions”. If the goal is to make the bot answer questions about new facts (like a 200-page manual), RAG is the correct and only reliable solution.
Fine-Tuning is for BEHAVIOR. Fine-tuning is not a reliable way to add new factual knowledge; the model will still hallucinate or “forget.” Instead, fine-tuning is used to change the style, tone, or structure of the model’s responses. Its primary use cases are:
-
Adopting a Personality: Training the bot to “apply the right tone” or enforce a consistent brand voice (e.g., professional, witty, empathetic).
-
Learning Domain-Specific Jargon: Teaching a model to “speak” in a specialized language, such as legal or medical terminology, that it may not have mastered in general training.
-
Task Specialization: Honing the model’s skill on a specific task, like improving its summarization capabilities or its ability to classify text.
This leads to a “cost inversion” trade-off.
Fine-tuning involves a massive upfront compute cost (a Capital Expenditure, or CapEx) but results in a model that is fast at runtime.
RAG is relatively cheap to set up, but it incurs a runtime cost (an Operational Expenditure, or OpEx) on every single query because it must perform an additional vector search step, adding latency and computational overhead.
The most advanced enterprise solution is, therefore, a hybrid approach.
An organization will first fine-tune a base model to adapt its behavior (to understand medical jargon and speak with an empathetic tone).
Then, it will implement a RAG system on top of that specialized model to feed it dynamic knowledge (e.g., today’s patient files or new research papers).
This hybrid architecture, sometimes called Retrieval-Augmented Fine-Tuning (RAFT), solves both problems, creating a bot that understands the specialized language of its domain and has access to the facts of its business.
Table 2: Decision Matrix: RAG vs. Fine-Tuning
| Criterion | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
| Primary Goal | Knowledge Injection. To provide the LLM with dynamic, factual, and proprietary information. | Behavior Modification. To change the LLM’s style, tone, or specialization on a task. |
| Data Type | Unstructured or structured documents (e.g., PDFs, web pages, FAQs) that are continuously updated. | A static, labeled dataset of “prompt-response” pairs that demonstrate the desired behavior. |
| Data Freshness | Excellent. Knowledge is dynamic and can be updated in real-time by adding/deleting documents in the vector DB. | Poor. Knowledge is static and “frozen” at the time of fine-tuning. Requires complete retraining to update. |
| Hallucination Risk | Low. Responses are grounded in retrieved facts. The bot can be forced to answer only from sources. | High. Model can still hallucinate or misrepresent the “knowledge” it was trained on. |
| Verifiability (Citations) | High. The bot can cite the exact document snippets it used to form its answer. | None. The “knowledge” is baked into the model’s parameters; it is impossible to trace an answer to a source. |
| Upfront Cost / Effort | Low. Simple RAG pipelines are not compute-intensive to set up. Requires data management skills. | Very High. Requires creating a high-quality labeled dataset and running compute-intensive training jobs. |
| Runtime Cost / Latency | Higher. Every query requires an additional vector search step, adding latency and compute cost per-prompt. | Lower. Once trained, the model has the same runtime cost as the base model. It is a single, fast inference step. |
| Example Use Case | A customer support bot answering questions about a 200-page, frequently-updated product manual. | A customer support bot that is trained to always respond in a “friendly, professional, and slightly witty” brand voice. |
Part 4: The Evolution of Autonomy: From Chatbots to AI Agents
While RAG and fine-tuning enhance the knowledge of a chatbot, a new paradigm is emerging in 2025 that enhances its capability.
The industry is rapidly moving from “chatbots” to “AI Agents”.
4.1 Defining the New Paradigm: Chatbots Talk, Agents Act
This distinction is the key to understanding the next generation of AI.
A Chatbot is primarily designed for conversational interaction. Its job is to “talk.” It excels at handling FAQs, answering questions, and guiding users through simple, predefined workflows.
An AI Agent is an autonomous system capable of reasoning, planning, and taking actions to achieve a goal. Its job is to “act”. It is a “self-sufficient system capable of planning and executing complex tasks autonomously”.
This represents a fundamental shift from Conversation-as-Interface to Conversation-as-Orchestration.
For a chatbot, the conversation is the purpose. For an agent, the conversation is merely the control mechanism for a far more complex, autonomous process.
When a user gives a command like, “Find 5 dance creators in Brazil with 100k+ followers”, they are not “chatting.” They are giving a command.
An AI agent is designed to receive this ambiguous, natural-language command and orchestrate a series of actions to fulfill it.

4.2 Core Capabilities of AI Agents
To “act” autonomously, an AI agent must possess three capabilities that traditional chatbots lack:
-
Planning and Reasoning: The agent can receive a complex, multi-step goal and reason about how to achieve it. It can analyze the goal, “break complex tasks into smaller steps,” and create a plan.
-
Persistent Memory: The agent maintains long-term memory, allowing it to “learn” from previous interactions and maintain context.
-
Tool Use: This is the game-changer. An agent can “interact with multiple tools”. These “tools” can be anything: the ability to execute code, call third-party APIs (like a weather API or a CRM), query a database, or search the web. This is what connects the LLM’s “brain” to the outside world and gives it the power to act.
4.3 The Rise of Agentic Frameworks: Orchestrating Autonomy
An LLM provides the “brain” for an agent, but a developer needs a framework to provide the “scaffolding”—the code that coordinates the agent’s memory, tools, and reasoning loop.
Three primary frameworks have emerged as the 2025 standards:
AutoGen (Microsoft): This framework’s philosophy is “multi-agent conversational orchestration”. It is designed for “an open discussion where any agent can talk to any other agent in flexible patterns”. It is powerful for research-grade flexibility and creating complex, dynamic, and emergent behaviors, though this flexibility can be complex to manage.
CrewAI: This framework’s philosophy is “role-based teams of agents”. It allows a developer to build a virtual “crew” of specialized agents (e.g., a “Researcher” agent, a “Planner” agent, a “Writer” agent) that collaborate to achieve a shared goal. It is praised for its “elegant teamwork,” simplicity, and rapid iteration.
LangGraph: An extension of the popular LangChain library, LangGraph’s philosophy is “deterministic orchestration”. It models agentic workflows as stateful, cyclic graphs. Each node in the graph is a task or tool, and the “explicit edges” define the exact flow of information.
This final point highlights the core trade-off for enterprise developers.
The flexibility of AutoGen and CrewAI leads to emergent (and potentially unpredictable) behavior.
LangGraph is designed to be “deterministic” and “replayable”.
For an enterprise in a regulated industry, the ability to audit, debug, and predict an agent’s behavior is non-negotiable.
This makes LangGraph a compelling choice for production-grade, reliable, and observable enterprise workflows, while AutoGen and CrewAI are exceptional for rapid, creative prototyping.
4.4 Agentic RAG: The Synthesis of Knowledge and Action
The RAG architecture (from Part 3) also evolves in this new agentic paradigm. It becomes “Agentic RAG.”
Traditional RAG is a static, one-shot pipeline: Query -> Retrieve -> Generate.
Agentic RAG is dynamic. The RAG pipeline is no longer the entire system; it is just a tool in the agent’s toolbox.
The agent can reason about when and how to use this tool. For example, an agent might:
-
Receive a query.
-
Reason that the query is ambiguous.
-
Ask the user a clarifying question (“Which product line are you referring to?”).
-
Receive the clarification.
-
Only then execute its “RAG tool” with the refined query to retrieve the correct information.
This turns RAG from a passive architecture into an active, intelligent, and managed process.
Table 3: Chatbot vs. AI Agent: A Paradigm Shift in Capability
| Capability | Traditional Chatbot | RAG-Powered Chatbot | AI Agent |
| Primary Goal | Conversation. To answer questions within a predefined script or by matching keywords. | Information Retrieval. To answer questions by retrieving and synthesizing external, factual data. | Goal Completion. To autonomously plan and execute complex tasks to achieve a user’s goal. |
| Core Function | “I can talk about {X}.” | “I can answer questions about {X}.” | “I can do {X} for you.” |
| Interaction Style | Reactive; follows a script. | Reactive; answers a query. | Proactive; can ask clarifying questions, plan, and execute multi-step actions. |
| Use of Tools | None. | One tool (RAG pipeline) that is part of a static architecture. | Dynamic Tool Use. Can reason, select, and orchestrate multiple tools (e.g., RAG, APIs, code execution). |
| Example Task | “Tell me your store hours.” | “Summarize your company’s Q4 earnings report from this PDF.” | “Book me a flight to Boston for next Tuesday, find a hotel under $300, and add it to my calendar.” |
Table 4: AI Agent Frameworks: LangGraph vs. CrewAI vs. AutoGen
| Framework | Core Philosophy | Architecture Style | Memory Support | Observability | Best For |
| LangGraph | Deterministic Orchestration. “Following a detailed map”. | Stateful Graph. A cyclic graph where nodes are tasks/agents and “explicit edges” define the flow. | State-based memory with built-in checkpointing for workflow continuity. | Excellent. Enables “replayable” debugging with visual traces and step-level telemetry. | Production-Grade Enterprise Workflows. Any application requiring high reliability, auditability, and deterministic control. |
| CrewAI | Role-Based Collaboration. “Managing a team”. | Multi-Agent Teams. Defined, specialized agents (e.g., “Researcher,” “Writer”) collaborate autonomously. | Structured, role-based memory with RAG support. | Good. Surfaced performance hot spots and isolates tasks by agent. | Rapid Prototyping & Team-Based Tasks. Building virtual teams for tasks like content creation or research. |
| AutoGen | Conversational Orchestration. “An open discussion”. | Flexible & Dynamic. Agents collaborate in flexible, conversational patterns. | Conversation-based memory, maintaining dialogue history for multi-turn interactions. | Fair. Offers raw transparency but can be “chat-heavy,” making precise debugging difficult. | Research & Development. Pushing the boundaries of emergent, multi-agent collaboration. |
Part 5: The Developer’s Toolkit: Platforms and Frameworks
Choosing the right development tool is a critical strategic decision that depends on team skillset, deployment needs, and the required level of customization.
The 2025 landscape is segmented into three clear categories.
5.1 The Development Spectrum: No-Code, Low-Code, and Pro-Code
The primary trade-off in platform selection is between “ease of use” and “control”:
No-Code/Low-Code Platforms: These platforms offer visual, user-friendly interfaces (e.g., drag-and-drop) and allow for extremely quick setup and deployment. They are ideal for marketers, business users, and non-coders, or for developers looking to build a rapid prototype. The necessary trade-off is “less flexibility”; the bot is constrained by the platform’s features.
Pro-Code Frameworks: This category offers “more power, more effort”. These are open-source libraries and frameworks for developers who need “fine-grained control”, the ability to write custom logic, and the option for on-premise deployment to protect data.
5.2 Analysis: No-Code & Low-Code Platforms
For teams prioritizing speed-to-market, this-space is dominated by several key players.
The most sophisticated platforms in this category, however, are Botpress and Voiceflow, which bridge the gap between low-code and developer-centric features.
A head-to-head comparison is essential for any team:
Botpress: An open-source, developer-focused platform. Its “LLMz” custom inference engine makes it natively LLM-powered. Its primary strengths are its deep customization, extensive pre-built integrations, and powerful multichannel support for over 10 platforms, including web, mobile, and messaging apps. It is the choice for developers who want a low-code starting point but demand high-ceiling customization.
Voiceflow: A visual platform that excels in ease of use and collaborative design for UX-focused teams. Its “drag-and-drop interface” is considered more beginner-friendly. Its standout, non-negotiable feature is its excellence in voice and telephony, making it the clear choice for building voice-based AI agents.
5.3 Analysis: Pro-Code Frameworks (The “Build-Your-Own” Stack)
For teams requiring full control, the pro-code stack involves combining several specialized, open-source frameworks.
It is critical to understand that these tools are not “competitors” but are, in fact, complementary “lego bricks” in a modern AI stack.
Hugging Face: This is the ecosystem and model store. It is not a chatbot platform, but rather the essential hub where developers acquire their “engine”. The Transformers library is used to download and load pre-trained, open-source models. The ecosystem also provides the tools to fine-tune these models on custom data.
LangChain: This is the component glue. LangChain is a modular framework for building LLM-powered applications. It is not a standalone platform but rather the “plumbing” that connects the LLM (from Hugging Face) to other components like memory, tools, and, most importantly, the RAG (Retrieval-Augmented Generation) pipeline. It is the primary tool for implementing the RAG and agentic workflows described in Parts 3 and 4.
Rasa: This is the dialogue chassis. As the “most popular open source framework” for AI assistants, Rasa provides a robust, pro-code chassis for enterprise-grade dialogue management. While traditionally focused on NLU/intent-based logic, Rasa has evolved for the LLM era with its new CALM (Conversationally-Aware Language Model) engine. CALM is Rasa’s strategic answer to the “control” problem: it combines flexible LLM reasoning with the “reliability of deterministic logic” and predefined “flows”. This creates a “steerable” experience that avoids the “risks of ungrounded LLM reasoning,” positioning Rasa as the safe, auditable, and on-premise-ready choice for enterprises.
An expert-level stack would combine all three:
-
Use Hugging Face to download and fine-tune an open-source model.
-
Use LangChain to build a complex RAG pipeline for that model.
-
Use Rasa (CALM) as the robust, enterprise-grade dialogue manager that decides when to call the LangChain RAG pipeline, providing a layer of deterministic control.
5.4 Critical 2025 Update: The Microsoft Ecosystem Migration
A time-sensitive, strategic-level analysis is required for any developer on the Microsoft/Azure stack.
In 2025, Microsoft is in the midst of a forced transition, unifying its entire AI strategy around its “Copilot” brand.
This has two major implications:
Low-Code: Microsoft Power Virtual Agents (PVA) has been rebranded and absorbed into Microsoft Copilot Studio. Copilot Studio is now the “end-to-end conversational AI platform” for building standalone agents and, more importantly, for extending the main Microsoft 365 Copilot with proprietary data and workflows.
Pro-Code: The long-standing Microsoft Bot Framework SDK is being replaced. Official support tickets for the Bot Framework SDK will no longer be serviced after December 31, 2025. The new, official pro-code framework is the Microsoft 365 Agents SDK. This new SDK is “unopinionated about the AI you use” and is designed from the ground up to build agents that plug into any channel, especially Microsoft 365 Copilot.
Any developer or team starting a new project on the Microsoft stack in 2025 must avoid the legacy Bot Framework SDK and build on the M365 Agents SDK and Copilot Studio platform.
Table 5: The 2025 Chatbot Platform Landscape: A Developer’s Guide
| Category | Platform / Framework | Best For (User Persona) | Key Feature / Use Case |
| No-Code | Tidio | Small Businesses | All-in-one live chat, chatbot, and marketing automation. |
| No-Code | Chatbase | Non-coders | The fastest way to “go from zero to chatbot.” Instantly builds a RAG bot from a knowledge base. |
| No-Code | ManyChat | Marketers | Specialized for social media; building bots for Facebook Messenger, Instagram, WhatsApp. |
| Low-Code | Microsoft Copilot Studio | Enterprise (Microsoft Stack) | Replaced Power Virtual Agents. Builds standalone bots and extends Microsoft 365 Copilot. |
| Low-Code | Voiceflow | UX Designers, Beginners | Voice & Telephony. Best-in-class, easy-to-use visual builder for voice agents. |
| Low-Code | Botpress | Developers (Prototyping) | Multichannel & Customization. Open-source platform with deep developer control and 10+ channel integrations. |
| Pro-Code | Hugging Face | AI Engineers, Data Scientists | The Ecosystem. The “model store” for downloading, fine-tuning, and deploying open-source models. |
| Pro-Code | LangChain | Python Developers | The “Glue.” The modular framework for connecting LLMs to memory, RAG pipelines, and agentic tools. |
| Pro-Code | Rasa | Enterprise Developers | The “Chassis.” Open-source, on-premise-ready platform for deterministic dialogue management via its CALM engine. |
| Pro-Code | M365 Agents SDK | Enterprise (Microsoft Stack) | The New Standard. Replaces the Bot Framework SDK (support ends 2025). Builds AI-agnostic agents that extend Copilot. |
Table 6: Platform Deep Dive: Botpress vs. Voiceflow (The Low-Code Leaders)
| Feature | Botpress | Voiceflow | Verdict & Key Snippet |
| Ease of Use | Good, but more developer-focused. | Winner. “Better for beginners because its interface is easier to use”. “Focuses on simplicity with a drag-and-drop interface”. | Voiceflow wins for non-technical users and rapid, simple prototyping. |
| AI Features | Winner. “Has more AI Features”. Powered by a native LLM-inference engine (LLMz) for complex logic. | Good, but more focused on standard AI agent deployment. | Botpress offers a higher ceiling for complex, LLM-native AI logic. |
| Customization | Winner. “Better for teams requiring extensive customization through code”. “Full control over bot design”. | Good for visual design, but less flexible for deep code customization. | Botpress is the clear choice for developers who need to get “under the hood.” |
| Voice & Telephony | ❌ Not supported. | Winner. “Offers Telephony as a channel”. “Excels for… ready-made AI voice integrations”. | Voiceflow is the only choice of the two for building voice-based assistants. |
| Multi-Channel | Winner. “Available on more channels”. Supports 10+ channels (web, mobile, messaging). | Primarily focused on website and voice/telephony. | Botpress is the superior choice for an omnichannel (text/web) customer support strategy. |
| Target Audience | Developers who need a low-code platform with high-ceiling customization. | UX designers, beginners, and teams focused on voice interactions. | The choice is use-case dependent: Botpress for complex, multichannel text bots; Voiceflow for voice and simplicity. |
Part 6: A Practical Guide to the Chatbot Development Lifecycle
Building a state-of-the-art chatbot in 2025 is a cyclical, multi-disciplinary process that extends far beyond coding.
It involves strategic design, new testing paradigms, and continuous, post-deployment monitoring.
6.1 Phase 1: Strategy and Conversational (UX) Design
This initial phase is the new bottleneck for success.
In the pre-LLM era, the bottleneck was technical (e.g., “Can my NLU understand this intent?”).
Today, foundational LLMs can understand most well-phrased intents.
The new failure point is design. A bot that sounds robotic, provides confusing options (violating “cognitive load theory”), or has no clear next step will fail, regardless of its powerful AI.
As one analysis of 2.3 million conversations concluded, “conversation design makes or breaks your bot’s performance”.
This implies that a modern development team must include skilled Conversation Designers, not just engineers.
The key steps in this phase are:
Define Purpose and KPIs: Before any design, clearly define the bot’s purpose. What business goal will it fulfill?. Identify clear use cases (e.g., customer support, sales) and establish measurable Key Performance Indicators (KPIs) (e.g., resolution rate, user satisfaction).
Define Bot Personality: A chatbot is a “conversational interface,” not a website. It must have a consistent personality, tone, and brand voice. A financial bot should sound formal and precise, while a retail bot might be more casual and friendly. This personality must be consistent in every message.
Map Conversation Flows: Map the complete user journey from start to finish. An effective flow follows specific, data-backed principles. The “3-2-1 Rule” is a proven best practice:
-
Maximum 3 sentences per message.
-
Maximum 2 questions at once.
-
Always provide 1 clear next step (e.g., a button or suggestion).
Design the Interface (Hybrid Input): An effective conversational UI must use a “mixed input” model, combining free-form text entry with buttons and quick replies. Buttons and replies act as “signposts” that guide the user, reduce cognitive load, and prevent them from getting “stuck”.
Plan for Failure (Gracefully): Every bot, no matter how intelligent, will fail. A good design plans for this.
-
Fallback Responses: Design clear and helpful fallback messages (“I didn’t understand that, but I can help with X, Y, or Z”).
-
Human Escalation: Always provide a clear, easy-to-find path to a human agent. Users should never feel “trapped” in a bot loop.
6.2 Phase 2: Training, Testing, and Evaluation
Once the design is set, the bot must be built and trained (using the RAG or fine-tuning methods in Part 3) and then rigorously tested.
Testing an LLM-based system introduces a new paradigm that is fundamentally different from traditional software Quality Assurance (QA).
The core challenge is the shift from deterministic to non-deterministic systems.
Traditional Bots were “highly predictable” and had “finite, defined scenarios.” A tester could write a unit test asserting that the input “hello” always produced the exact output “Hi, how can I help?”
LLM-Based Bots have “non-deterministic outputs” and “infinite possible conversations.” The input “hello” might produce “Hi, how can I help?”, “Hello! What’s on your mind today?”, or “Hey there!”—all of which are correct.
This breaks traditional QA.
Testing is no longer about “pass/fail” on exact string matching. It has evolved into a probabilistic evaluation of output quality against a new set of metrics.
While standard tests for integrations, performance, and security are still required, a new suite of LLM-specific evaluation metrics is now mandatory:
-
Factual Accuracy / Hallucination Detection: Does the bot generate false or misleading information?.
-
Context Retention / Knowledge Retention: Does the bot remember key details from earlier in the conversation?.
-
Role Adherence / Consistency: Does the bot maintain its defined personality and tone? Or does it “break character”?.
-
Conversation Relevancy: Is the response on-topic, relevant, and helpful to the user’s query?.
-
Confidence Calibration: Does the bot know when it doesn’t know? A well-calibrated bot should have a high “I don’t know” rate for out-of-scope questions, rather than guessing.
Table 7: Chatbot Evaluation Metrics: Traditional vs. LLM-Based Systems
| Testing Aspect | Traditional Rule-Based Bots | Modern LLM-Based Bots |
| Predictability | Highly predictable. Input A always yields output B. | Non-deterministic. Input A can yield B1, B2, or B3. |
| Test Case Creation | Finite, defined scenarios based on “happy paths” and known rules. | Infinite possible conversations. Must test for behavioral patterns, not specific strings. |
| Response Validation | Exact String Matching. assert(response == "Expected"). |
Semantic Similarity Assessment. assert(is_response_helpful_and_factual). |
| Key Risks | Limited context awareness; easily “broken” by typos or slang. | Hallucination. High risk of generating false facts with confidence. |
| Core Evaluation Metrics | Accuracy, Response Time, Intent Classification F1-Score. | Relevance, Coherence, Safety, Faithfulness, Context Retention, Role Adherence. |
6.3 Phase 3: Deployment, Integration, and Monitoring
The final phase of the lifecycle is a continuous loop of deployment, integration, and improvement.
Deployment (Omnichannel Strategy): A bot should be deployed where the users are. This means an “omnichannel” approach:
-
Website: Embedded via widgets.
-
Mobile Apps: Natively integrated using tools like React Native or Flutter.
-
Messaging Apps: Connected via APIs to WhatsApp, Facebook Messenger, Slack, and Telegram.
Integration (The Value-Add): A chatbot that is not integrated with backend systems is little more than a “smart FAQ.” The true enterprise value is unlocked through deep integration with systems like CRMs, ERPs, and knowledge bases. This integration is what allows a bot to move from “answering questions” to “automating workflows,” such as pulling real-time order status from a CRM.
Monitoring (The Continuous Loop): Deployment is the beginning, not the end. A chatbot is not a “set it and forget it” project. An effective team must implement a continuous monitoring loop:
-
Track Metrics: Monitor KPIs defined in Phase 1, such as user satisfaction, query resolution time, and engagement levels.
-
Review Conversation Logs: This is the most valuable source of data. Review the logs to identify where users drop off, get “stuck,” or what questions the bot fails to answer.
-
Iterate and Improve: Use this user feedback and data analytics to continuously update the bot’s knowledge base (for RAG), refine its conversation flows, and improve its performance.
Part 7: A Curriculum for Continuous Learning (The “Training” Guide)
The user query requested “training.” In the field of generative AI, “training” is not a one-time event but a continuous process.
The technologies and frameworks discussed in this report are evolving monthly.
A successful developer or team must commit to a two-pronged learning strategy: building a strong formal foundation and engaging in real-time developer-led learning.
7.1 Formal Education: Courses & Certifications
Formal courses are excellent for mastering the foundational, stable concepts (e.g., Transformer architecture, RAG principles, Conversation Design theory).
Broad AI/LLM Foundations:
-
Coursera: The “Generative AI with Large Language Models” specialization (a collaboration between DeepLearning.AI and AWS) is a modern standard. Andrew Ng’s foundational “Machine Learning” course remains the best starting point for understanding core concepts.
-
Udemy: “The AI Engineer Course 2025: Complete AI Engineer Bootcamp” provides a comprehensive, practical overview of the entire stack, including Python, NLP, LLMs, LangChain, and Hugging Face.
-
Microsoft: Offers a free “Generative AI for Beginners” course that covers the fundamentals of the new generative paradigm.
Chatbot & Conversation Design Specializations:
-
IBM: Offers free, hands-on courses via platforms like SkillsBuild and Coursera, including “Build Your Own Chatbots” and “Building AI-Powered Chatbots”.
-
Conversation Design Institute (CDI): This is the industry-leading certification body for the non-engineering side of development. It offers specialized certifications for “Conversation Designer,” “AI Trainer” (the role responsible for curating RAG and fine-tuning data), and “AI Ethics”. This reflects the “T-Shaped” skillset now required, where deep Conversational UX & Design skills are as critical as programming.
University Programs (Deep Expertise):
-
For those seeking deep, formal expertise, universities are now offering specialized graduate programs. A notable example is Northeastern University’s Master of Professional Studies in Applied AI, which offers a dedicated “concentration in Conversational AI and Chatbots”. Other universities like St. Thomas and Indiana University offer similar degrees covering NLP and bot development.
7.2 Developer-Led Learning: The Bleeding Edge
In 2025, formal courses will always lag the bleeding edge of AI development.
The “true” training and real-time innovation happen in open-source communities.
Trends like “multi-agent orchestration” emerge from GitHub projects months or years before they appear in a textbook.
For a developer, “training” is a continuous process of monitoring these “living” resources:
Essential GitHub Repositories (The “Textbooks”):
-
awesome-llm-apps: A curated repository of cutting-edge applications demonstrating advanced AI Agent, RAG, and Multi-agent Team patterns.
-
awesome-chatgpt: A massive collection of demos, SDKs, open-source UIs, and tools built around the generative AI ecosystem.
-
Source Code: Reading the source code of frameworks like Auto-GPT, OpenAgents, and the agentic frameworks in Part 4 is a primary learning tool.
Developer Communities (The “Labs”): This is where real-world problems are solved in public, daily.
-
r/LLMDevs: A subreddit for advanced technical discussions. Developers here are actively debating the RAG vs. fine-tuning trade-offs and building new stacks.
-
r/LangChain: The official community for the LangChain framework, essential for troubleshooting agent and RAG pipelines.
-
r/LocalLLaMA: The primary community for developers working with open-source, locally-run models. This is where discussions on fine-tuning, quantization, and the business viability of open-source AI happen.
Key Technical Blogs (The “News”):
-
Staying current requires following the primary sources, such as the blogs from OpenAI and MIT News, and specialized technical writing blogs like “I’d Rather Be Writing”, which focus on API documentation—a critical component of any bot’s knowledge base.
This curriculum underscores a new reality: the single job of “chatbot developer” has fragmented.
A successful team in 2025 must be “T-shaped,” combining a broad, horizontal understanding of the full stack (Python, ML, frameworks) with deep, vertical specializations in both engineering (e.g., “AI Engineer”) and design (e.g., “Conversational UX Designer,” “AI Trainer”).
The “training” never stops, and the “classroom” is now GitHub.
Conclusions and Strategic Recommendations
This report has detailed the end-to-end process of training and building intelligent AI chatbots in 2025, moving from foundational principles to advanced agentic architectures.
The analysis reveals a landscape defined by rapid evolution, new architectural paradigms, and a fundamental shift in the developer’s role.
Based on this exhaustive analysis, several strategic recommendations are clear for any technical lead or organization entering this space:
Prioritize NLU and Conversational UX (ConUX): The “intelligence” of a 2025 bot is perceived through its NLU—its ability to understand nuance, emotion, and context. Its usability is defined by its ConUX. An investment in a state-of-the-art LLM will be wasted if it is paired with a poorly designed, “robotic” conversation flow. Therefore, the Conversation Designer is now one of the most critical roles on a development team.
Embrace a “RAG-First” Hybrid Architecture: The “RAG vs. Fine-Tuning” debate has a clear enterprise solution. A “RAG-first” approach should be the default for all proprietary, dynamic, and factual knowledge. It is more transparent, easier to update, and safer from a data-governance perspective. Fine-tuning should be reserved as a specialized, secondary tool for modifying behavior, such as adopting a brand voice or learning domain-specific jargon. The expert-level system will combine both.
Choose Agentic Frameworks Based on Determinism: The future of chatbots is “AI Agents” that can act. When selecting an agentic framework, the primary strategic choice is between emergence and determinism. While flexible, multi-agent conversational frameworks like AutoGen are powerful for R&D, enterprises (especially in regulated fields) should default to deterministic graph-based frameworks like LangGraph. Its “replayable” and auditable nature makes it the most viable for production-grade, reliable, and observable workflows.
Execute the Microsoft Stack Migration (If Applicable): For teams on the Microsoft/Azure stack, this is a non-negotiable, time-sensitive directive. The Bot Framework SDK is now legacy, with support ending in 2025. All new development must be on Microsoft Copilot Studio (low-code) and the Microsoft 365 Agents SDK (pro-code) to align with the company’s unified Copilot-centric strategy.
Commit to Continuous, Open-Source-Led Learning: “Training” is no longer a static, one-time event. The most critical, bleeding-edge innovations in this field (e.g., new RAG techniques, agentic orchestration) are emerging from open-source GitHub repositories and developer communities months before they are formalized in courses. A team’s “training” program must be a continuous, active process of monitoring, experimenting, and contributing to this open-source ecosystem.

