
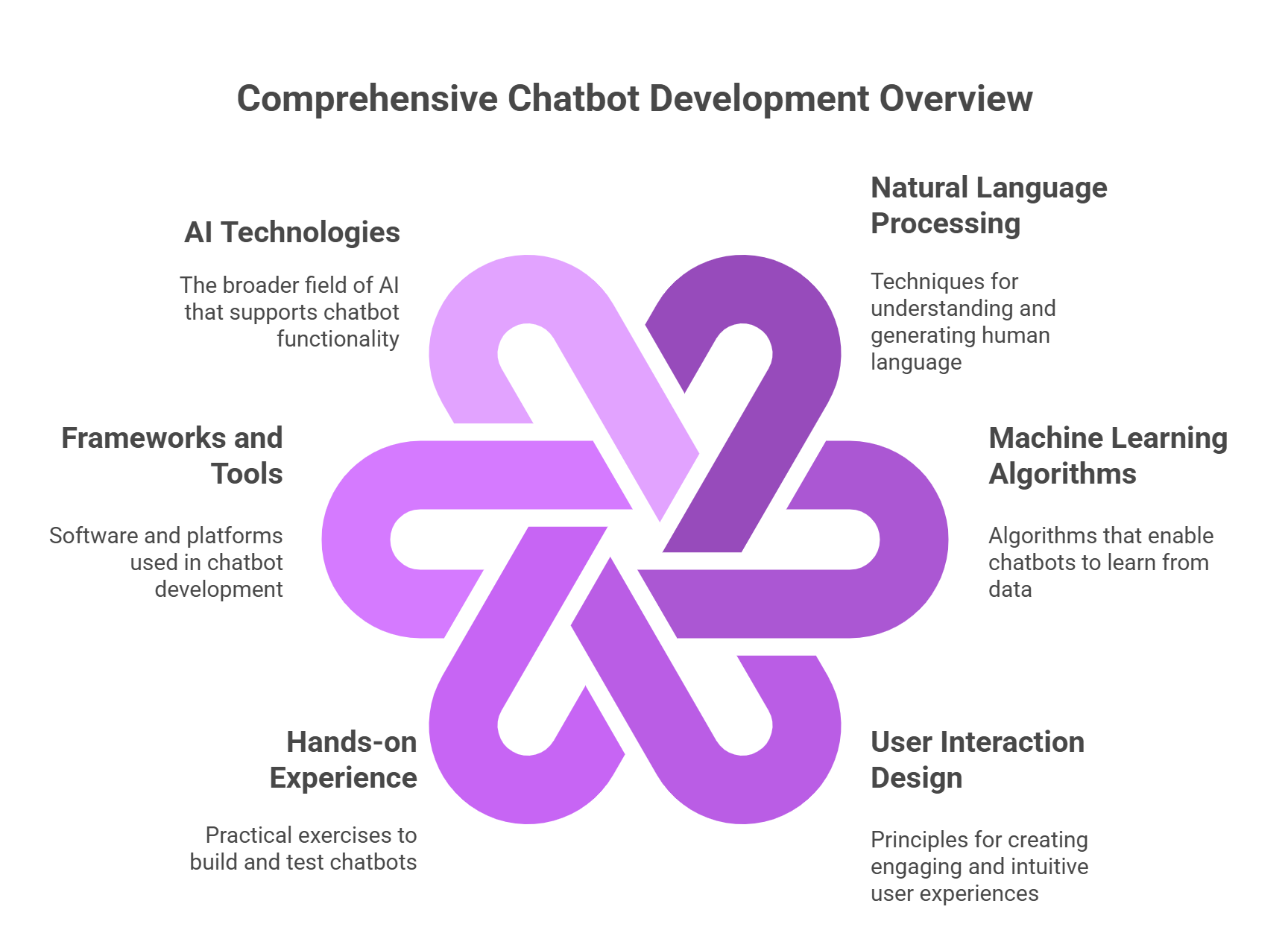
Here is a comprehensive, SEO-optimized engineering guide tailored for the 2025 landscape of AI development.
Building Intelligent Chatbots in 2025: The Ultimate Engineering Guide to RAG, Agents, and Advanced Architectures
The domain of conversational artificial intelligence has undergone a radical transformation.
Gone are the days of simple pattern-matching scripts that frustrated users with generic fallback responses.
As of 2025, the engineering landscape is defined by cognitive architectures capable of reasoning, autonomous decision-making, and dynamic tool utilization.
For developers and architects, the challenge has shifted from simply “making it talk” to making it accurate, safe, and context-aware.
This guide provides a blueprint for constructing state-of-the-art conversational agents, moving from architectural selection to granular implementation using the modern Python ecosystem.
The New Architectural Standard: RAG vs. Fine-Tuning
The most critical decision an AI architect faces today is selecting the right architecture.
Historically, developers had to choose between rigid retrieval systems and creative but hallucination-prone generative models.
Today, the industry standard has coalesced around Retrieval-Augmented Generation (RAG) and Agentic Workflows.
Understanding the Generative vs. Retrieval Dichotomy
Generative models (like early GPT versions) are incredible at linguistic fluency but suffer from “hallucinations.”
They confidently generate factually incorrect information because their knowledge is frozen at the moment of training.
RAG resolves this by decoupling reasoning from knowledge storage.
In a RAG architecture, the LLM acts as a reasoning engine, while a vector database serves as the dynamic knowledge base.
This ensures your chatbot always has access to the latest proprietary data without expensive retraining.
Decision Framework: When to Use What
Is RAG always the answer? Not necessarily.
Sometimes, Fine-Tuning is required to teach a model a specific behavior or “procedural” knowledge, such as speaking in a specific medical code or JSON format.
Below is a comparison to help you choose the right path:
| Feature | RAG (Retrieval-Augmented Generation) | Fine-Tuning | Hybrid (RAFT) |
| Primary Mechanism | Dynamic context injection at inference. | Static weight adjustment via training. | Fine-tuned model + Retrieval context. |
| Knowledge Freshness | Real-time (instant updates). | Static (requires re-training). | Hybrid (Static core + Dynamic edge). |
| Hallucination Risk | Low (grounded in context). | Medium (reduced but possible). | Lowest. |
| Best Use Case | Customer support, Enterprise search. | Medical diagnosis, Legal drafting. | Complex domain reasoning with live data. |
Pro Tip: Recent trends point toward Retrieval-Augmented Fine-Tuning (RAFT). This hybrid approach fine-tunes a model specifically to be better at using retrieved context, ignoring distractors in document chunks.
The 2025 Python AI Stack and Ecosystem
Constructing a modern chatbot requires navigating a complex ecosystem of libraries.
Python remains the undisputed foundation of this stack.
Here are the essential components you need to master.
Orchestration and Logic Layers
-
LangChain: The standard for chaining LLM calls. It allows you to swap components (like changing OpenAI to Anthropic) with minimal code changes.
-
LlamaIndex: Specialized for the data layer. It offers advanced data structures for indexing massive document sets, making it superior for heavy RAG applications.
-
LangGraph: The new standard for stateful, cyclic graph applications. Unlike linear chains, LangGraph enables agents to loop, retry, and maintain state..
The Knowledge Layer: Vector Databases
The efficiency of a RAG system hinges on its vector store.
Pinecone and Weaviate are excellent managed solutions for enterprise deployment, handling sharding and replication automatically.
For local development or strict data sovereignty, Chroma and FAISS are the preferred open-source choices.
The Cognitive Layer: Model Selection
-
Proprietary Models: GPT-4o and Claude 3.5 Sonnet currently lead in reasoning capabilities and context window size.
-
Open Weights Models: Llama 3 (Meta) and Mistral are the democratized alternatives.
-
Optimization: Using techniques like QLoRA, Llama 3 can be hosted on private infrastructure, ensuring complete data privacy.
Step-by-Step Implementation: Building the Core
Let’s move from theory to practice.
We will outline the engineering steps to build a memory-aware bot using Python and Streamlit.
Phase 1: Managing Conversation Memory
A “stateless” bot treats every query as an isolated event, which is a poor user experience.
However, appending every previous message to the prompt will quickly exhaust your token budget.
You must implement a Sliding Window Strategy.
This involves keeping only the last K interactions (e.g., the last 5 turns) to ensure the model stays focused on immediate context while discarding stale data.
Here is a conceptual snippet for enforcing token budgets:
def enforce_token_budget(messages, budget=2000):
"""
Implements a Sliding Window Strategy.
Removes oldest messages while preserving System Prompt.
"""
current_tokens = sum(count_tokens(m["content"]) for m in messages)
while current_tokens > budget:
if len(messages) <= 2:
break # Safety break
messages.pop(1) # Remove oldest user/assistant exchange
current_tokens = recalculate_tokens(messages)
return messages
Phase 2: The Ingestion Pipeline
Before your bot can answer questions about your documents, data must be processed.
This involves Chunking and Embedding.
-
Load: Import documents using loaders like
PyPDFLoader. -
Split: Use
RecursiveCharacterTextSplitter. Do not split by page; split by semantic boundaries (paragraphs/sentences). -
Embed: Convert chunks into vectors using OpenAI embeddings or HuggingFace models.
-
Store: Save these vectors into your FAISS or Pinecone index.
Phase 3: The Retrieval Chain
The magic happens when you connect the vector store to the LLM.
We utilize the ConversationalRetrievalChain.
This chain performs a vital step called Query Re-writing.
If a user asks “What is its battery life?” the system uses chat history to rewrite this to “What is the battery life of the MacBook Pro M3?” before searching the database.
The Frontier: Agentic Workflows and Autonomy
The most advanced chatbots of 2025 operate as Agents.
Unlike passive chains that follow a linear path, Agents utilize a cyclic graph architecture.
They can reason, plan, and correct errors autonomously.
Implementing Self-Correcting RAG with LangGraph
LangGraph allows us to define a state machine for the chatbot.
This architecture mitigates the “garbage in, garbage out” problem of simple RAG.
Here is the logic flow for a self-correcting agent:
-
Retrieve: Fetch documents based on the query.
-
Grade: An LLM evaluates if the documents are actually relevant.
-
Loop/Fallback: If irrelevant, the agent rewrites the search query and tries again, or triggers a web search tool.
This capability transforms chatbots from passive interfaces into active assistants capable of performing multi-step workflows.
Production Engineering: Safety and Observability
Building the bot is only half the battle; deploying it safely is the other half.
Safety Guardrails with NVIDIA NeMo
Allowing an LLM to interact with customers without guardrails is risky.
NVIDIA NeMo Guardrails provides a programmable safety layer.
You can configure “Rails” to enforce strict behavioral rules:
-
Topical Rails: Prevent the bot from discussing competitors or politics.
-
Safety Rails: Detect and block PII or toxic language.
-
Jailbreak Rails: Identify adversarial prompts designed to bypass safety filters.
Evaluation with RAGAS
The era of “eye-balling” chatbot performance is over.
You must use quantitative metrics to ensure quality.
Frameworks like RAGAS (Retrieval Augmented Generation Assessment) evaluate your pipeline using an “LLM-as-a-Judge” approach.
Key metrics to monitor include:
-
Faithfulness: Is the answer derived only from the retrieved context?
-
Answer Relevance: Does the answer actually address the user’s query?
-
Context Recall: Did the retrieval system find the necessary ground truth?
Conclusion and Implementation Checklist
The monolithic chatbot is dead.
The future belongs to systems composed of specialized agents, grounded in vector memory, and orchestrated by graph-based logic.
By adhering to the architectures and technologies outlined in this guide, organizations can build conversational AI that is a transformative business asset.
Use this checklist to ensure your 2025 chatbot project is on the right track:
-
Architecture: Default to RAG; use Fine-Tuning only for specific format adaptation.
-
Stack: Python + LangChain + Pinecone + OpenAI/Llama 3.
-
Memory: Implement Sliding Window Memory to balance context and cost.
-
Agency: Upgrade to LangGraph for multi-step reasoning tasks.
-
Safety: Deploy NeMo Guardrails to prevent jailbreaks.
-
Observability: Integrate RAGAS metrics and LangSmith tracing from Day 1.

